Comment mieux comprendre les usages des logiciels métiers pour en améliorer la qualité et l’expérience utilisateur ?
L’analyse des traces de navigation dans les logiciels RH, ou de gestion financière permet d’identifier les parcours réels, les points de friction et les leviers d’amélioration. Un défi d’autant plus complexe que les données sont souvent techniques, hétérogènes, peu annotées, sans profils riches, et où la réglementation et la complexité métier rendent chaque évolution délicate.
Après quatre années de thèse CIFRE menée entre l’Université de Toulouse – IRIT et Berger-Levrault, Ikram Boukharouba, ingénieure de recherche au sein du Groupe, a soutenu avec succès un doctorat en informatique sur ce sujet stratégique. Ses travaux ouvrent de nouvelles perspectives pour faire évoluer les solutions Berger-Levrault au plus près des besoins des utilisateurs.
Dans un premier article publié sur le site BL.Research « Usage discrepancies: when business software meets real life », Ikram analyse les écarts d’usage entre le « scénario idéal » prévu lors de la conception de logiciels métiers et la réalité du travail quotidien, et ce que ces écarts signifient pour leur conception.
Ce deuxième article passe du principe au cas concret avec l’exemple de la gamme de solutions logicielles SEDIT dédiée aux collectivités locales de taille moyenne et grande.
La démarche consiste à enregistrer les traces de navigation, reconstruire les parcours utilisateurs et comparer, de manière quantitative, ce que le logiciel devrait voir (les scénarios présents dans les cahiers de tests) et ce qu’il voit réellement lorsque les agents des collectivités l’utilisent au quotidien.
Pour y voir clair, nous avons construit deux environnements de SEDIT.
Nous sommes partis des cahiers de tests fonctionnels de SEDIT, qui décrivent les principaux scénarios métier : créer un dossier, traiter une absence, valider une décision, etc. Ces scénarios ont été rejoués manuellement dans le logiciel, et toutes les interactions ont été enregistrées par notre outil interne de traçabilité, SOFTSCANNER.
Résultat : 62 sessions qui incarnent l’usage prescrit, celui que SEDIT est censé supporter.
Cette fois, nous travaillons sur des traces de sessions d’agents en situation de travail, dans différents modules de SEDIT.
Nous disposons ainsi de 239 sessions « naturelles », où les utilisateurs font ce qu’ils ont à faire, avec leurs urgences, leurs habitudes et parfois leurs bricolages.
La question n’est plus seulement « que font les utilisateurs ? », mais : les trajectoires théoriques dessinées par la conception se retrouvent-elles dans cet univers de trajectoires réelles ?
Comparer des centaines de séquences de navigation une par une serait illisible.
Nous avons donc choisi une approche inspirée du machine learning : transformer chaque session en un vecteur, appelé embedding, c’est-à-dire un point dans un espace latent.
L’idée est intuitive : si deux sessions racontent une histoire de navigation similaire, avec les mêmes écrans et une logique d’enchaînement comparable, leurs vecteurs devraient être proches. À l’inverse, si un scénario prescrit ne ressemble à aucun usage réel, son vecteur risque de se retrouver isolé.
Pour construire ce « paysage » de comportements, nous avons utilisé trois méthodes complémentaires.
Au final, chaque session prescrite ou réelle devient un point dans un espace de grande dimension. Nous obtenons ainsi deux nuages de points : celui des parcours théoriques issus de SOFTSCANNER, et celui des parcours réels observés dans SEDIT.
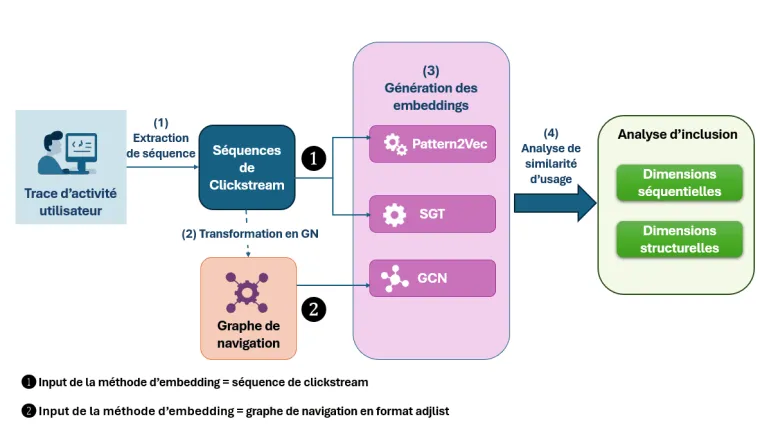
Chaîne de traitement : à partir des traces d’activité, nous construisons des séquences de parcours de clics (clickstream), des graphes de navigation, puis des représentations vectorielles de session (embeddings) afin de comparer l’usage prescrit avec l’usage réel.
Plutôt que de se demander si les utilisateurs suivent la procédure à la lettre — question à laquelle la réponse est presque toujours négative — nous avons adopté une formulation plus réaliste : les parcours prescrits sont-ils présents dans l’ensemble des parcours réels ?
Autrement dit, les scénarios décrits dans les cahiers de tests réapparaissent-ils quelque part dans les traces de navigation quotidiennes ? Chaque parcours théorique retrouve-t-il au moins un « cousin » proche dans les usages observés ?
À ce stade, comparer les deux environnements revient à comparer deux nuages d’embeddings. Nous avons analysé cette relation à deux niveaux.
Dit autrement, il ne s’agit pas de vérifier que les utilisateurs jouent la partition note à note, mais de voir si les thèmes principaux composés lors de la conception sont bien présents dans le concert des usages réels.
Au-delà des courbes et des distances, plusieurs enseignements se dégagent.
D’abord, une bonne nouvelle pour les concepteurs : les cahiers de tests fonctionnels ne racontent pas une fiction. Les scénarios modélisés pour SEDIT capturent bien la colonne vertébrale des usages réels. Les briques de navigation imaginées à la conception se retrouvent dans la pratique.
Ensuite, une nuance importante : la réalité est plus riche que le modèle. Les utilisateurs recomposent, combinent et contournent. Ils insèrent des détours, enchaînent plusieurs tâches dans une même session et adaptent les parcours à leurs contraintes. Les scénarios prescrits apparaissent donc moins comme des scripts à suivre au mot près que comme des lignes directrices autour desquelles les pratiques s’organisent.
Enfin, ces écarts deviennent une ressource. Lorsqu’un type de parcours est très fréquent dans les logs mais peu représenté dans les tests, il signale un usage réel important mais insuffisamment outillé. À l’inverse, certains scénarios très présents dans les spécifications apparaissent rarement dans la réalité, ce qui interroge leur pertinence actuelle.
Ce type d’analyse ouvre plusieurs perspectives concrètes pour un éditeur de logiciels métier comme Berger-Levrault :
Il ne s’agit plus seulement de vérifier que l’utilisateur suit la procédure, mais de faire évoluer cette procédure pour mieux épouser les pratiques réelles, réduire les frictions inutiles et améliorer concrètement l’expérience de travail.
L’étude de la gamme SEDIT montre qu’entre usage prescrit et usage réel, il n’y a ni rupture totale ni alignement parfait. Il existe un espace commun, fait de conformité partielle, de contournements intelligents, de rituels et d’innovations discrètes. Les utilisateurs composent avec les scénarios de conception, les réinterprètent et les ajustent à leurs contraintes.
Grâce aux traces d’usage, aux graphes de navigation et aux embeddings, cet espace intermédiaire devient visible et exploitable. Ce qui pouvait apparaître comme du bruit devient un signal utile pour faire évoluer le produit.
Accepter que l’utilisateur idéal n’existe pas, ce n’est pas renoncer à la qualité logicielle ; c’est changer de point de vue sur la manière de l’atteindre. Plutôt que de forcer le terrain à entrer dans le modèle, il s’agit de laisser le modèle s’enrichir de ce que montre le terrain, afin de concevoir des systèmes qui assument pleinement la vraie vie des professionnels. C’est dans cette logique que Berger-Levrault fait évoluer ses solutions, au plus près des usages des collectivités.
 Tous les pays
Tous les pays
 France
France
 Maroc
Maroc
 Espagne
Espagne
 Canada - En
Canada - En